•比较批量和连续数据摄入
•介绍Snowpipe
•使用云消息配置Snowpipe
•使用和监控Snowpipe
•使用Snowflake动态表连续转换数据
在本章中,我们将构建一个新的数据管道,该管道能够最小延迟地持续从外部云存储中出现的文件中摄入数据。
我们将解释连续和批量数据摄入之间的差异,这已在前几章中描述。我们将介绍Snowpipe作为Snowflake数据管道中用于连续数据摄入的特性。最后,我们将使用动态表来连续执行数据转换。
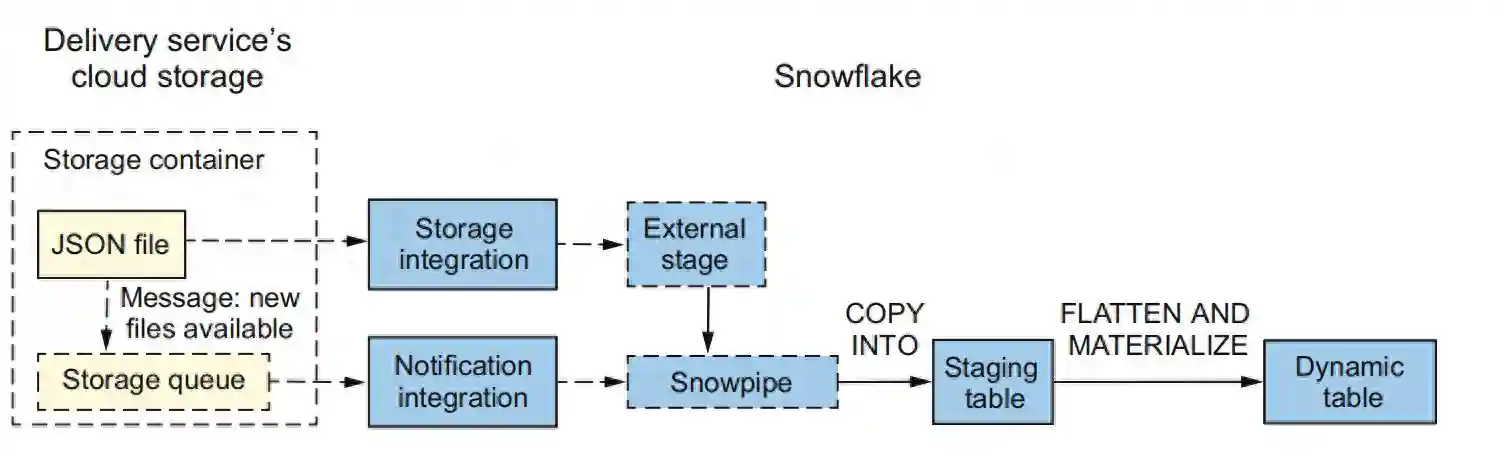
我们将构建一个使用Snowpipe从存储在外部云存储位置的JSON文件中摄入数据的数据管道。我们将把数据从JSON格式转换为关系格式。与第4章执行存储过程不同,我们将通过创建动态表来实现数据的物化。
为了说明本章构建数据管道所使用的示例,我们将继续使用第2章中介绍的虚构面包店。简单回顾一下,面包店制作面包和糕点,并将这些烘焙食品送到附近的便利店、咖啡店和餐馆等小企业。
由于面包店没有在线订购系统,客户通过电子邮件下订单,面包店将这些订单存储在本地文件系统上的CSV文件中。一些面包店客户每天通过CSV或JSON文件提供订单信息,这些文件存储在他们云存储平台的专用容器中。为了摄入所有这些文件,面包店的数据工程师构建了通过内部或外部阶段访问文件的管道。这些管道将数据从文件中摄入到Snowflake表中,并根据需要进行转换。这些管道被安排每天晚上运行一次,在工作时间之后,以便第二天可以使用新鲜的订单信息。
面包店正在进一步扩大其业务。它与一家食品配送服务签约,该服务在城市内配送食品订单。由于配送服务全天候在工作时间运营,面包店不能像现有的数据管道那样等待每日文件摄入,因为他们需要随时从配送服务获取订单信息。数据工程师必须构建一个新的数据管道,该管道可以全天候连续摄入数据。
食品配送服务有一个云存储平台,将订单保存在JSON格式的文件中。面包店的数据工程师将构建一个类似于第4章中描述的从酒店云存储中摄入JSON格式订单文件的数据管道。这两个管道的主要区别在于,我们每天一次性摄入酒店的文件,但使用Snowpipe摄入服务连续摄入食品配送服务的文件。
注意:本章的所有代码和示例数据文件都可以在随附的GitHub仓库中找到,位于。
为了构建一个从云存储中摄取食品配送服务文件数据的管道,面包店数据工程师将创建一个外部阶段,以便将数据文件提供给Snowflake。他们将使用一个存储集成对象与配送服务的云存储提供商一起使用。这一步与第4章中描述的从云存储摄取数据相同。
然后,将创建一个Snowpipe并与云存储提供商的通知服务集成。每当新的文件到达云存储时,都会向队列发送一个通知,允许Snowpipe意识到并摄取新文件。
在本章的后续部分将更详细地解释如何使用云消息传递配置Snowpipe。最后,一个动态表将实现从JSON格式文件中摄取的扁平化数据。所描述的数据管道如图5.1所示。
批量数据加载指的是定期安排的数据管道,这些管道将数据摄入到Snowflake表中。这些管道通常安排在每天晚上或夜间运行。当新数据以已知间隔到达,或者数据消费者不需要最新数据,而是可以使用前一天的数据时,这种类型的数据加载是有用的。
当消费者需要更频繁地获取数据时,数据管道可以安排在更短的时间间隔内运行——例如,每小时或每几分钟一次。这种频繁安排数据管道的方法通常被称为微批处理。如果整个管道在下一次预定执行之前完成执行,这种方法是可行的。实际上,这通常不会足够快地发生以满足用户需求,因为管道不能以少于整个管道执行时间的间隔进行安排。
作为在微批处理中安排数据管道的替代方案,Snowflake提供了Snowpipe功能,该功能旨在在文件一出现在阶段中时立即加载数据。Snowpipe在使用COPY命令从文件加载数据到Snowflake表的行为上类似于微批处理,不同之处在于它不是通过时间间隔来安排,而是通过事件触发。为了正确运行,Snowpipe可以配置云消息传递,当新文件到达时发送通知,触发管道执行。
5.2在云存储中准备文件为了构建一个数据管道,该管道能够持续从食品配送服务的云存储中摄入文件,我们将首先创建一个存储集成对象,就像我们在第4章构建从云存储中摄入酒店订单的数据管道时所做的那样。和酒店一样,食品配送服务使用微软Azure作为云存储提供商。在本章中,我们将使用微软Azure来说明示例。
在AmazonS3或GoogleCloudStorage中创建存储集成Snowflake文档提供了关于在AmazonS3和GoogleCloudStorage中设置存储集成的详细信息,网址为(AmazonS3)和(GoogleCloudStorage)。
如果你正在使用自己的MicrosoftAzure账户跟随学习,你可以为本章的练习准备存储在blob存储中的文件。你需要通过执行以下步骤在你的账户中创建资源:
1.创建一个资源组,或者如果你已经有一个并且想用于练习,可以使用现有的资源组。你可以随意命名资源组。
2.在资源组中创建一个存储账户。
注意:在选择存储账户的名称时,请记住它必须在Azure中是唯一的。本章的练习使用speedyorders001作为存储账户的名称。如果你想给你的存储账户起一个类似的名字,但该名字已被占用,请将后缀从001改为其他数字组合,并相应地修改任何代码。
3.创建一个容器。你可以随意命名容器,但如果你想按照本章练习中的命名,就将其命名为speedyservicefiles。
资源准备就绪后,你可以导航到speedyservicefiles容器,并从GitHub仓库的Chapter_05文件夹中上传几个名为Orders_2023-09-04_12-30-00_12345.json、Orders_2023-09-04_12-30-00_12346.json和Orders_2023-09-04_12-45-00_12347.json的示例文件到存储容器中。
提示:尽管GitHub仓库中有更多的文件,但现在只上传几个样本文件到blob存储容器。稍后,当我们将演示Snowpipe如何在新文件一出现在云存储中就加载它们时,你会上传更多的文件到存储容器中。
5.2.1创建存储集成食品配送服务必须提供以下与他们的存储账户相关的信息,这些信息是创建存储集成所必需的:
•Azure租户ID
•存储账户的名称
•存储容器的名称
在我们的例子中,Azure租户ID是1234abcd-xxx-56efgh78(这是一个用于说明目的的虚构租户ID),存储账户是speedyorders001,容器是speedyservicefiles。
使用这些信息,我们可以使用以下命令创建SPEEDY_INTEGRATION存储集成:

就像在第四章中,我们将执行DESCRIBEINTEGRATION命令并记录下AZURE_CONSENT_URL和AZURE_MULTI_TENANT_APP_NAME属性。然后我们将与食品配送服务的Azure管理员合作,他们将接受Snowflake服务主体并授予存储容器的权限。
一旦我们创建了存储集成,并且Azure管理员在Azure中完成了授权步骤,我们就可以使用它来创建一个外部阶段。我们将授予SYSADMIN角色对存储集成对象的使用权限,我们将使用它来创建外部阶段并构建管道,通过执行以下命令:
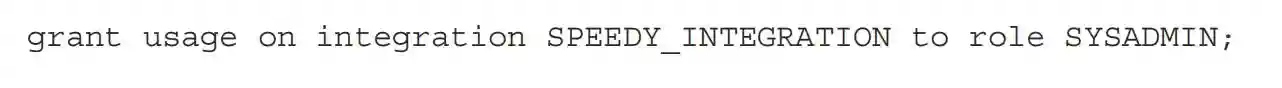
提示在这些初始章节中,我们为了简化起见,使用SYSADMIN角色在Snowflake中创建对象。通常,数据工程师会在Snowflake账户中设置自定义角色,但由于我们尚未创建任何自定义角色,我们将使用内置角色。
5.2.2创建外部阶段
然后,我们将使用SPEEDY_INTEGRATION存储集成创建一个名为SPEEDY_STAGE的外部阶段。我们将提供从食品配送服务接收的存储容器中文件的位置(存储账户的名称是speedyorders001,容器的名称是speedyservicefiles)。因为我们知道文件是JSON格式的,我们将提供FILE_FORMAT参数为type=json。我们可以执行以下命令来创建外部阶段:

要查看外部舞台的内容,我们可以执行以下命令:

此命令的输出将显示食品配送服务已经上传到blob存储容器的任何文件。如果你正在跟随操作,LIST命令将显示你之前上传到存储容器的文件。
通过执行SQLSELECT命令,我们可以查看暂存文件中的数据:

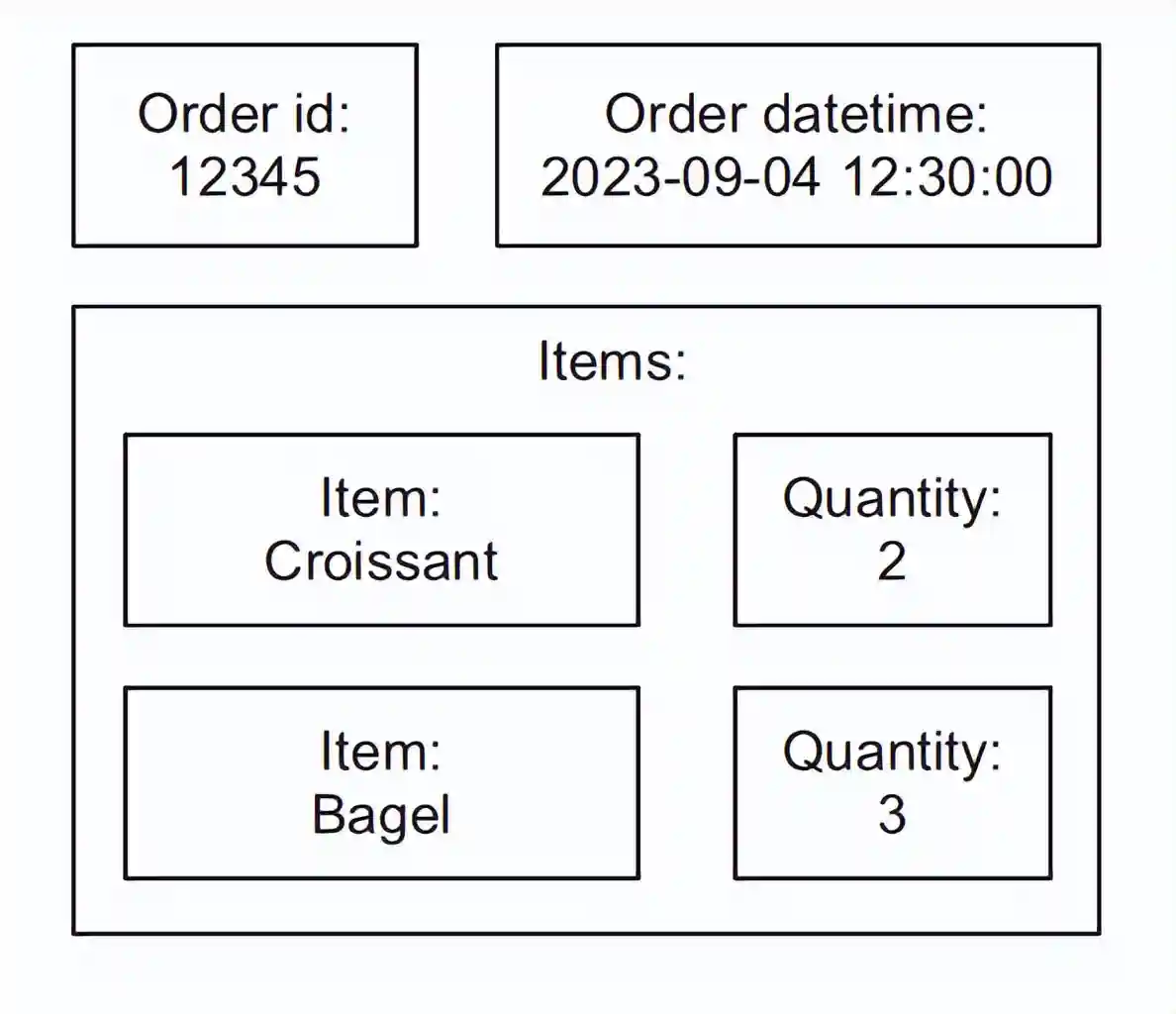
此命令的输出显示了一个包含JSON格式数据的变体列,这些数据存储在外部存储中的文件里。下面的列表显示了JSON数据结构的一个示例。

如我们在列表5.1中所见,层级结构的最高层有三个JSON键值对,键名为“Orderid”、“Orderdatetime”和“Items”。"Items"键的值是一个键值对列表,键名为“Item”和“Quantity”。图5.2展示了JSON结构的图形表示。